[TIL] 230516 머신러닝의 기본개념
1.머신러닝(Machine Learning)이란?
[알고리즘]
수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차 - 위키피디아
[머신러닝]
1959년, 아서 사무엘은 기계 학습을 "기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야"라고 정의
경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구로, 인공지능(AI)의 한 분야로 간주된다.
컴퓨터(machine)가 학습(learning)할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다.
머신러닝의 핵심은 표현(representation)과 일반화(generalization)에 있다. 표현이란 데이터의 평가이며, 일반화란 아직 알 수 없는 데이터에 대한 처리이다. - 위키피디아
[딥러닝]
비선형 변환기법의 조합을 통해 높은 수준의 추상화(abstractions, 다량의 데이터나 복잡한 자료들 속에서 핵심적인 내용 또는 기능을 요약하는 작업)를 시도하는 기계 학습 알고리즘의 집합으로 정의 - 위키피디아
머신러닝의 필요성
문제에서 고려할 변수가 적을 경우, 알고리즘을 기반으로 사람이 풀이가 가능했다.
하지만, 고려할 변수와 경우의 수가 많아져 사람의 능력으론 어려움이 발생했다. → 컴퓨터한테 시켜보자!
그래서 주어진 데이터를 답습하여 컴퓨터 스스로 결론을 도출하는 컴퓨터(machine)+학습알고리즘(learning) = 머신러닝 이 개발되었다.
딥러닝(Deep learning)은 머신러닝에 활용되는 기법 중 하나로, 빅데이터와 접목하여 비선형적인(정비례관계가 아닌) 다량의 데이터를 학습하여 머신러닝의 학습알고리즘으로 사용하는 방법이다.
결국, 개발과정에서 기능구현(문제해결)을 위해 대량의 데이터(big data)를 컴퓨터(machine)에게 딥러닝(Deep learning)이라는 방법을 통해 학습시키는 것(learning)이 앞으로 익혀갈 부분이다!
- 인공지능(Artificial intelligence): 인공지능은 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술입니다. 인공지능은 강인공지능과 약인공지능으로 나눌 수 있습니다.
- 머신러닝(Machine Learning): 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 사이킷런이 대표적인 라이브러리입니다.
- 사이킷런(scikit-learn): 2007년 구글 썸머 코드에서 처음 구현되었으며, 가장 널리 사용되는 머신러닝 패키지 중 하나입니다.
- 인공 신경망(Artificial Neural Network): 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘입니다. 신경망은 기존의 머신러닝 알고리즘으로 다루기 어려웠던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목 받고 있으며 종종 딥러닝이라고도 부릅니다.
- 딥러닝(Deap learnging): 딥러닝은 인공 신경망이라고도 하며, 텐서플로(TensorFlow)와 파이토치(PyTorch)가 대표적인 라이브러리입니다.
2. 머신러닝 접근방식 - 회귀/분류
회귀 (Regression) - 입력값을 넣었을 때, 출력값을 연속적인 값으로 예측하게 하도록 푸는 방법
ex) 특정인물사진(input) → 인물의 나이(output)<float>
분류 (Classification) - 입력값을 넣었을 때, 출력값을 특정 분류값으로 예측하게 하도록 푸는 방법
입력값(input)과 출력값(output)을 보고 회귀인가 분류인가, 문제를 정의하고 접근하는 것이 좋다.
3. 머신러닝 학습방법 - 지도 학습/비지도 학습/강화 학습

지도 학습(Supervised Learning)
정답을 알려주면서 학습시키는 방법
input(데이터)에 따른 output(정답)이 결정되어있어서, 그 값들을 학습시켜 정답을 예측하도록 하는 방식
장점 +
- 비교적 학습방법이 쉽고, 학습시간이 짧게 걸리며 정확도가 높다.
단점 -
- 출력값이 존재해야만 학습이 가능하다.
- 입력값에 따른 출력값을 연결지어주는 라벨링(Labeling, 레이블링) 과정이 필요하다.
비지도 학습(Unsupervised Learning)
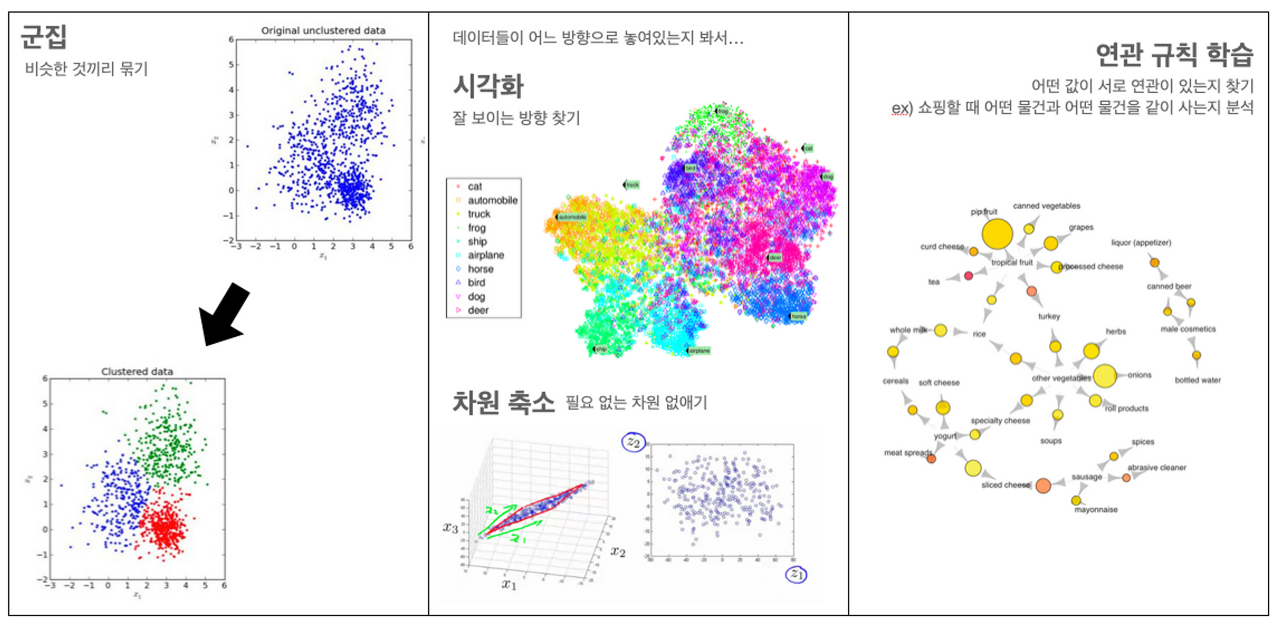
정답을 알려주지 않고 군집화(Clustering)하는 방법
input(데이터)에 따른 output(정답)이 결정되어있지 않고, 그 값들을 학습시켜 정답을 예측하도록 하는 방식
+비지도학습의 종류
- 군집 (Clustering)
- K-평균 (K-Means)
- 계측 군집 분석(HCA, Hierarchical Cluster Analysis)
- 기댓값 최대화 (Expectation Maximization)
- 시각화(Visualization)와 차원 축소(Dimensionality Reduction)
- 주성분 분석(PCA, Principal Component Analysis)
- 커널 PCA(Kernel PCA)
- 지역적 선형 임베딩(LLE, Locally-Linear Embedding)
- t-SNE(t-distributed Stochastic Neighbor Embedding)
- 연관 규칙 학습(Association Rule Learning)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
장점 +
- 출력값이 없어도 학습이 가능하다.
- 추가적인 라벨링(Labeling, 레이블링) 과정이 불필요하다.
단점 -
- 비교적 학습방법이 어렵고, 학습시간이 오래 걸리며 정확도가 낮다.
강화 학습(Reinforcement Learning)
주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법
input(데이터)에 따른 output(정답)이 결정되어있지 않지만, output에 따라 reward(보상)를 부여하며 학습시켜 정답을 예측하도록 하는 방식
- 에이전트(Agent) : 자신이
- 환경(Environment) : 주어진 조건 속에서
- 상태(State) : 현재 상태에서
- 보상(Reward) : 높은 점수를 받도록
- 행동(Action) : 행동을 결정 | 단, 행동 목록은 사전에 정의되어야한다.
장점 +
- 경우의 수가 매우 많은 빅데이터의 경우에 적합한 학습방법이다.
- 상대적으로 더욱 복잡한 문제의 경우 유리하다.
단점 -
- 상대적으로 학습시간이 오래걸린다.
- 일정 이상의 데이터가 충족되지 않으면 제대로 된 결과를 보기 힘들다.